CEN: CESCA


El hardware
El CESCA dispone de tres computadores de altas prestaciones:
- IBM SP2: 12 + 32 procesadores (42 thin160 y
2 wide), 12 GB de memoria principal, 494 GB en
disco y un rendimiento punta de 27,41 Gflop/s.
- Hewlett-Packard Exemplar V2500: 16 procesadores PA8500 (440 MHz), 8 GB de memoria principal, 216 GB
en disco y un rendimiento punta de 28,16 Gflop/s.
- Hewlett-Packard N4000: 8 procesadores PA8500 (también a 440 MHz), 4 GB de memoria principal, 227 GB
en disco y un rendimiento punta de 14,08 Gflop/s.
Todas las mįquinas tienen procesadores superescalares pero se diferencian en el acceso a memoria: el SP2 tiene una memoria
distribuida, mientras que las otras dos son de memoria compartida.
La interconexión procesadores-memoria del V2500 es mediante un crossbar de 8x8 de 15,3 GB/s y la de la N4000 son
dos buses con una velocidad agregable total de 3,8 GB/s. Esta interconexión proporciona una latencia a memoria mucho
mįs rįpida que la V2500 (130 ns versus 550 ns).
El rendimiento mįximo para resolver un sistema de ecuaciones lineal
(Rmax) es, respectivamente, de 16,17, 17,47 y 10,22 Gflop/s.
Gracias al convenio de creación del
Centre de Computació i Comunicacions de Catalunya el hardware del CEPBA
también estį disponible a nuestros usuarios: la Origin2000, la Alphaserver 8400 y el Parsytec CCi.
Características técnicas y rendimiento de los diversos procesadores
|
| IBM SP2
wide
| IBM SP2
thin160
| HP V2500
PA8500
| N4000
PA8500
|
| Frecuencia (MHz)
| 66
| 160
| 440
| 440
|
| Ancho de bus
| 256
| 256
| 64
| 64
|
| Cache datos (KB)
| 256
| 128
| 1.024
| 1.024
|
| R.punta (Mflop/s)
| 266
| 640 (2,41)
| 1.760 (6,62)
| 1.760 (6,62)
|
| LINPACK TPP
| 236
| 532 (2,25)
| 1.047 (4,44)
| 1.290 (5,47)
|
| LINPACK 100x100
| 130
| 315 (2,42)
| 375 (2,88)
| 375 (2,88)
|
| SPECint95
| 3,8
| 8,61 (2,26)
| n/d
| 34,0 (8,95)
|
| SPECfp95
| 12,4
| 25,8 (2,08)
| n/d
| 51,4 (4,14)
|
Glosario
Los procesadores superescalares pueden iniciar la ejecución simultįnea de varias instrucciones escalares en paralelo de manera que se pueden
operar varios elementos de un vector dentro de una misma iteración. En nuestro caso, el PA8500 puede iniciar cuatro y los del SP2, seis.
Si la memoria estį compartida entre todos los procesadores, es decir, hay un espacio śnico de direcciones para todos, entonces la programación es
muy sencilla ya que los datos se pueden colocar en cualquier módulo de memoria i el acceso es uniforme para todos los procesadores.
Si la memoria estį distribuida entre los procesadores, es decir, cada procesador tiene acceso a su propia memoria, entonces la programación
es mįs compleja ya que cuando los datos a usar por un procesador estįn en el espacio de direcciones de oltro, serį necesario sol.licitarlas y transferirlas a través
de mensajes. De este modo, es necesario impulsar la localidad de los datos para minimizar la comunicación entre procesadores y obtener un buen rendimiento.
La ventaja que proporcionan es su escalabilidad, es decir, el sistema puede crecer a nśmero mayor de procesadores que los sistemas de memoria compartida y,
por lo tanto, es mįs adecuado para las mįquinas paralelas.
Hay un tercer tipo de organización, la memoria distribuida compartida, que combina las ventajas de ambas organizaciones: la memoria estį fķsicamente
distribuida y, por lo tanto, el sistema es escalable, pero se accede con un espacio śnico de direcciones y, en consecuencia, es fįcilmente programable.
Para optimizar el rendimiento de un supercomputador, uno de los factores a considerar es el tamańo de la memoria cache disponible por procesador:
- Para la SP2, el tamańo depende del tipo de procesador. Para los 42 thin160, 128 KB; y para los 2 wide, 256 KB.
- Para el PA8500 de la V2250, 1 MB.
El rendimiento de los supercomputadores se mide en Gflop/s: 1 Gflop/s indica que el procesador realiza
operaciones aritméticas (tipo sumas o multiplicaciones) de nśmeros reales, codificados en formato de coma flotante de 64 bits, por segundo.
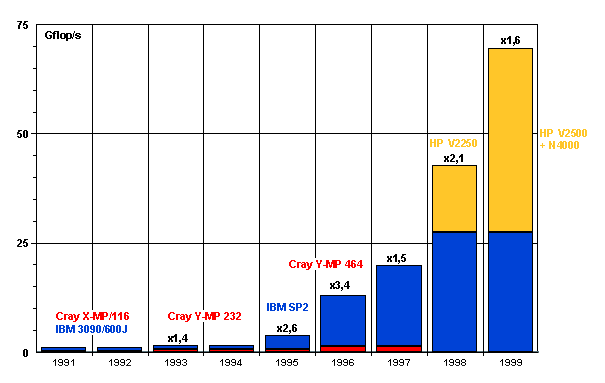
Una visión histórica del hardware disponible
© CESCA, MH/220496/041199
Diapositiva 25
19-23 de Junio de 2000
